본격적으로 엑셀로 데이터 분석을 하기에 앞서 데이터 분석의 단계를 알아보자. 우선 목적을 설정해야 한다. 무턱대고 데이터를 모으고 데이터를 분석해갈 수는 없다. 할 수도 있겠지만 방향성도 없고, 동기부여도 되지 않을 것이다. 목적을 설정하고 나면 그 목적에 부합하는 데이터를 수집하고, 가공하고, 분석하고, 정리해야 한다. 정리에는 눈에 잘 들어오도록 시각화하는 부분까지 포함한다. 이번 포스팅에서는 서울 열린데이터 광장의 공공데이터를 이용해서 데이터 수집과 가공 부분까지 살펴보려고 한다. 서울 열린데이터 광장에는 서울시의 시정활동 중 수집된 여러 종류의 데이터가 존재하며, 자유로운 사용이 허용된 데이터를 모아놓은 곳이다.
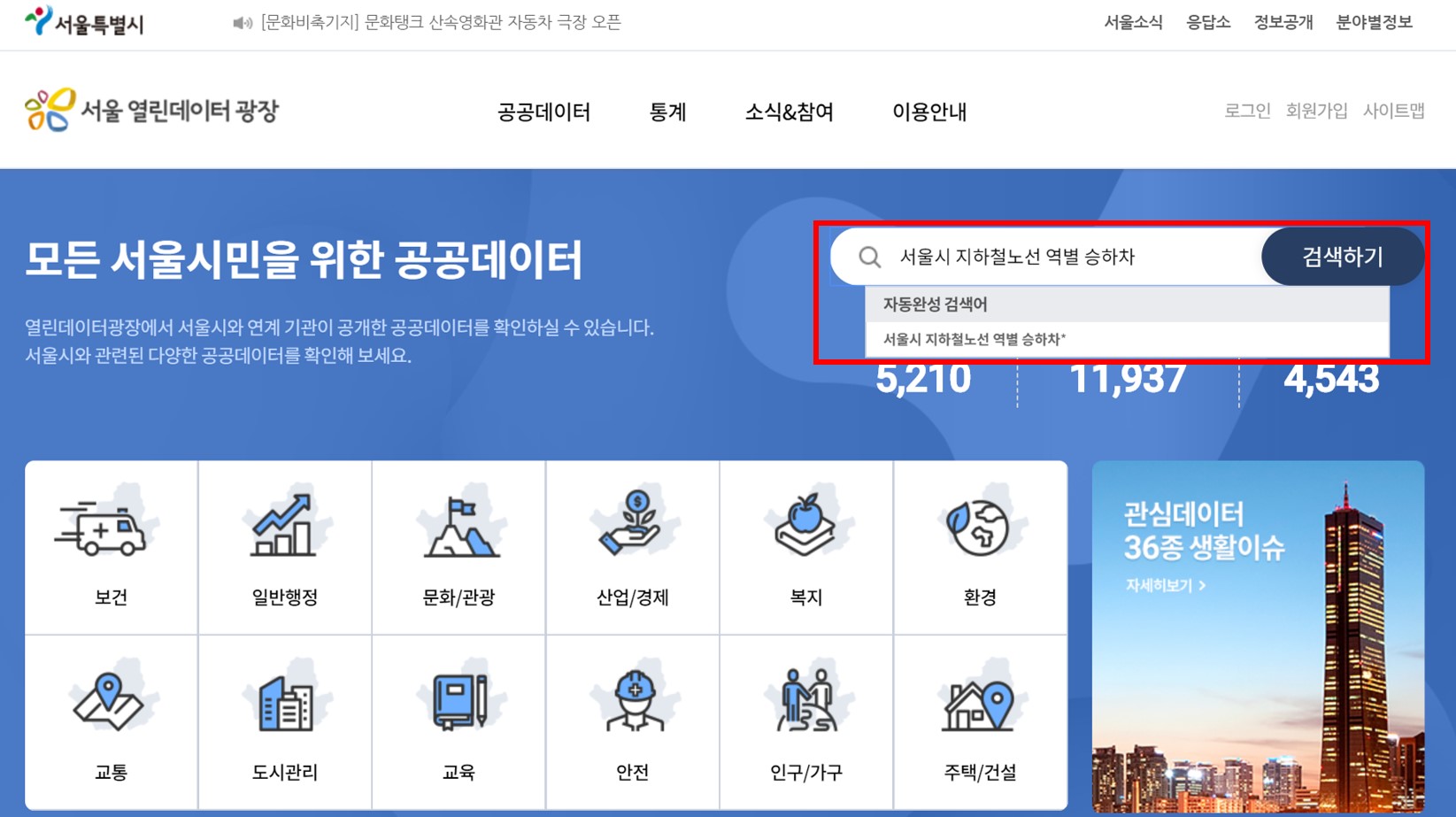
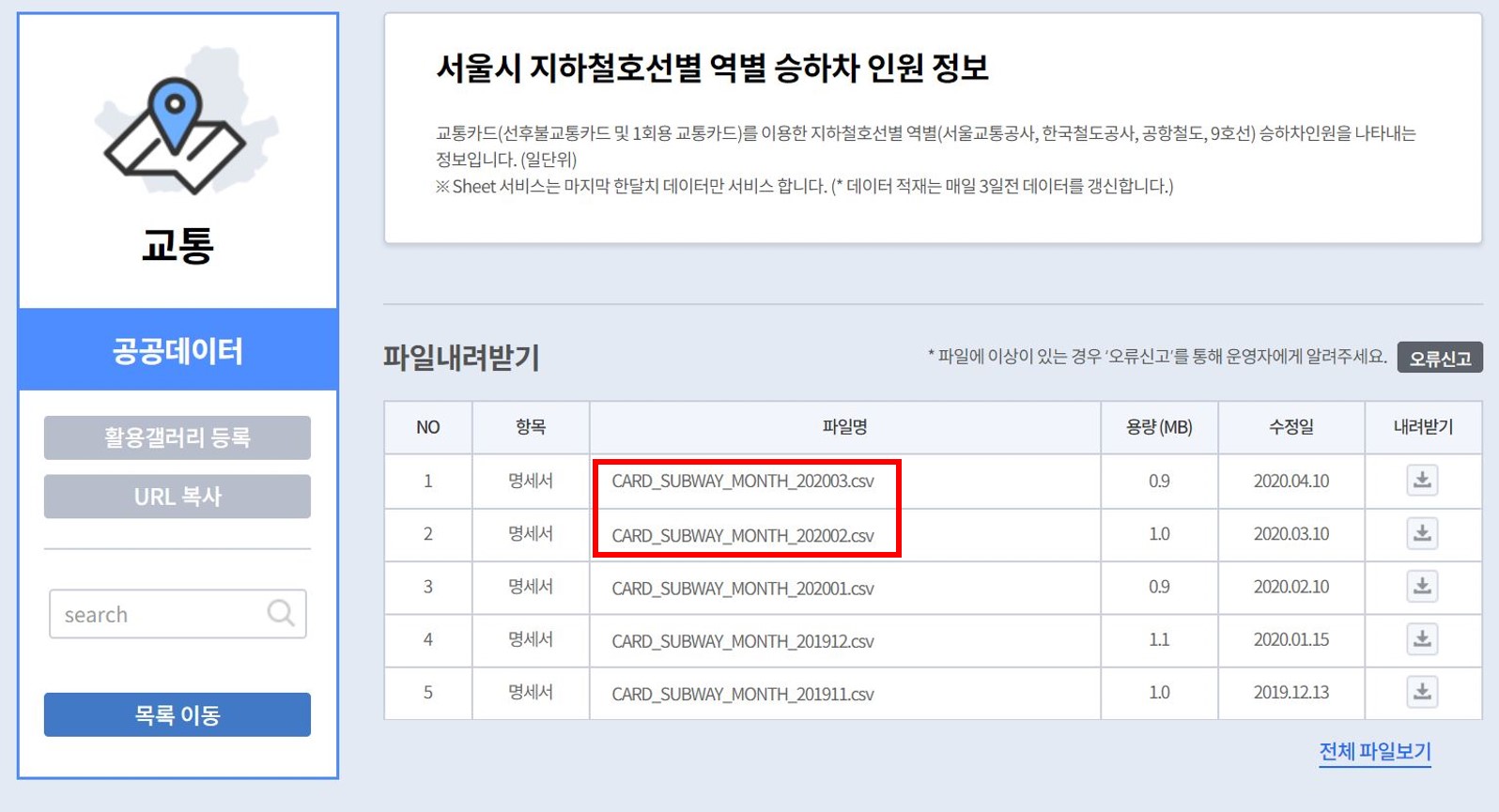
이 포스팅에서 다뤄볼 분야는 서울시 지하철호선별 역별 승하차 인원 정보이다. 함께 해 볼 사람들은 위 링크에서 ‘CARD_SUBWAY_MONTH_202003.csv’ 파일을 다운받거나, 메인화면 검색창에서 ‘서울시 지하철노선 역별 승하차’를 검색하고 위 파일을 다운받으면 된다.
목적 설정
우선 목적을 설정해보자. 최근 코로나19로 인해 재택근무를 시행하는 기업들이 늘어났고 대중교통이 다소 한산해졌다는 반응들이 있었다. 실제로 지하철 이용객이 얼마나 감소했는지 정확히 확인하는 것을 목적으로 세운다. 데이터의 범위를 좁히기 위해 기간은 2월 23일부터 3월 22일까지 한달로, 노선은 2호선으로 한정한다. 2월 23일은 코로나19에 대한 위기경보 수준이 심각으로 격상된 날로 사회적 분위기가 크게 형성된 날이고, 2호선은 순환선으로 서울의 중심부 주요구간을 지나는 목적으로 만들어진 노선이기 때문이다.
데이터 수집 및 가공
다음은 수집단계인데 이 데이터는 이미 수집이 끝난 자료이므로 수집 후 반드시 필요한 데이터가공 작업을 간단히 설명하겠다. 후가공은 수집만큼 무척 중요한데, 이 데이터만 봐도 월별로 데이터가 정리되어 있는데 지금 설정한 목적에 맞게 데이터를 보려면 2월과 3월의 데이터를 합쳐야 한다. 마케팅 업무를 수행하는 분들은 각자 사용하는 솔루션에서 기존에 관리하던 데이터 수집기준이 있을 것이다. 이럴 경우에는 후가공을 하지 않아도 될 만큼 수집될 데이터를 정밀하게 다듬을 수 있었겠지만, 보통의 경우는 수집된 데이터를 분석하기 좋게 가공하는 작업이 필요하다. 분석의 주체가 수집의 기준도 결정하게 된다면 많은 고민이 수반되는 작업일 수 있다. 하지만 데이터 분석의 효율성을 위해서 반드시 필요하다.
가공작업 실습
실제 분석으로 돌아가서, 2월 이용현황(CARD_SUBWAY_MONTH_202002.csv) 파일과 3월 이용현황(CARD_SUBWAY_MONTH_202003.csv) 파일을 다운로드 받는다. 두 파일을 열어보면 사용일자, 노선명, 역ID 등 동일한 기준으로 수집이 되어있다.
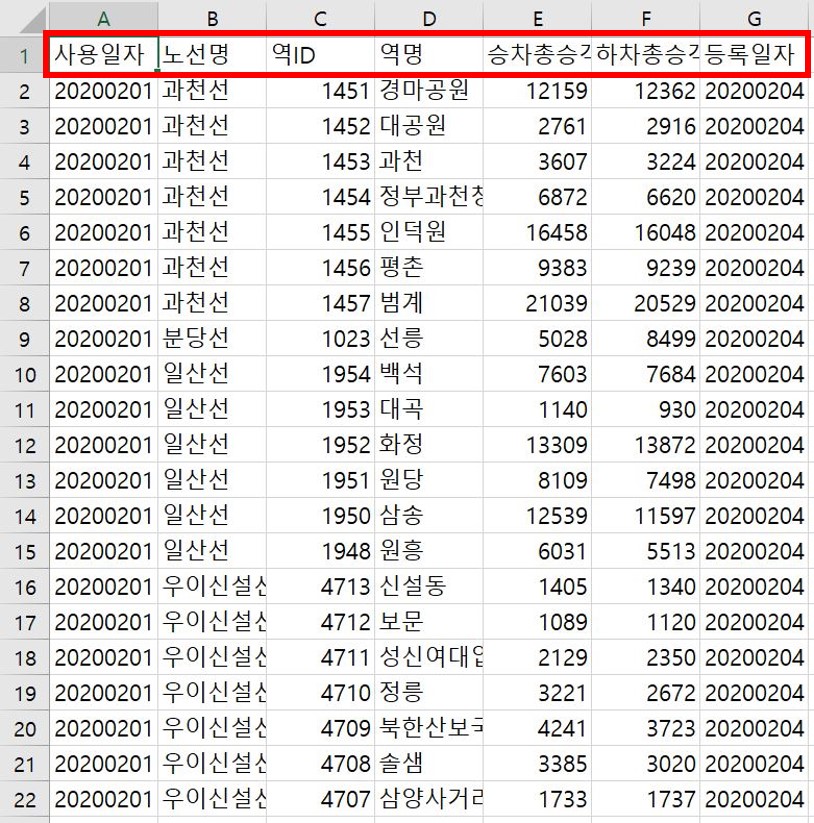
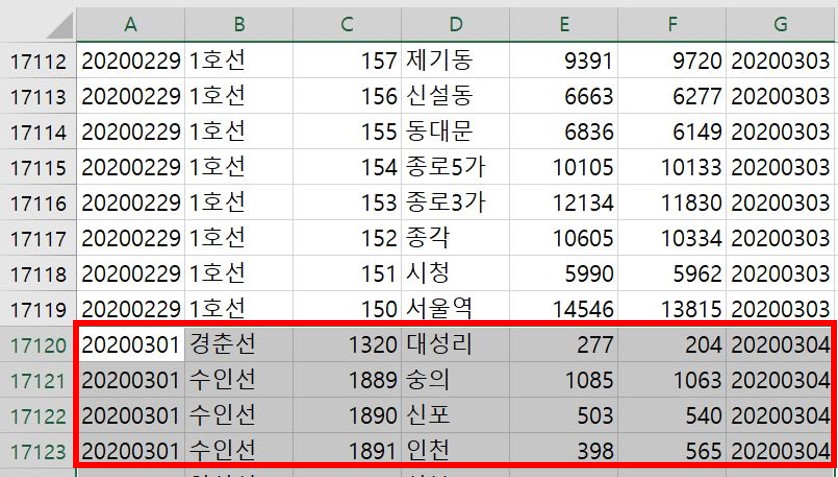
2월과 3월의 이용현황을 한 파일에서 보기 위해, 3월 파일에서 기준을 제외한 내용들을 2월 파일의 가장 최하단에 복사, 붙여넣기 한다. 사용일자, 노선명, 역ID 등만 제외하고 나머지 내용들을 붙여넣는다는 뜻이다.
그리고나서 시트에 나열된 데이터들을 표로 만들어준다. 표로 만들어주면 작업하기에 더욱 수월해진다. 방법은 데이터를 모두 선택하고(Ctrl+A) 단축키 Alt+N+T를 누르거나 상단의 메뉴 중 ‘삽입 > 표’를 선택하면 된다.
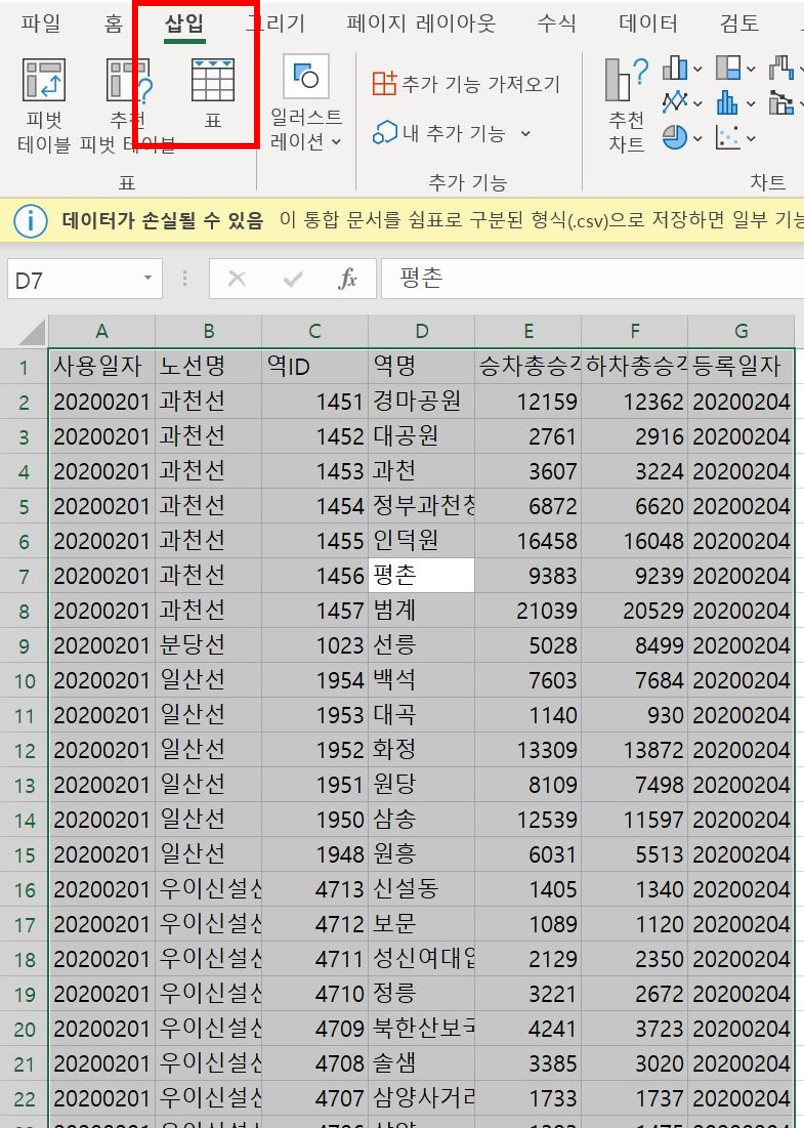
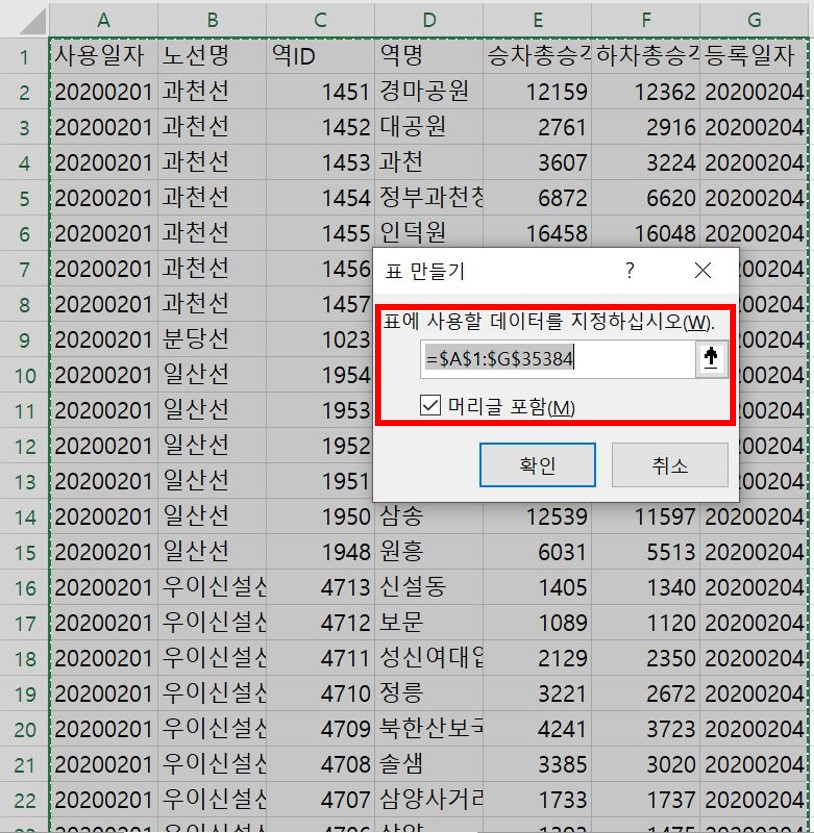
표에 사용할 데이터의 범위를 Ctrl+A로 먼저 지정해주었으니 별도의 범위 지정 없이 확인 버튼을 누르면 된다.
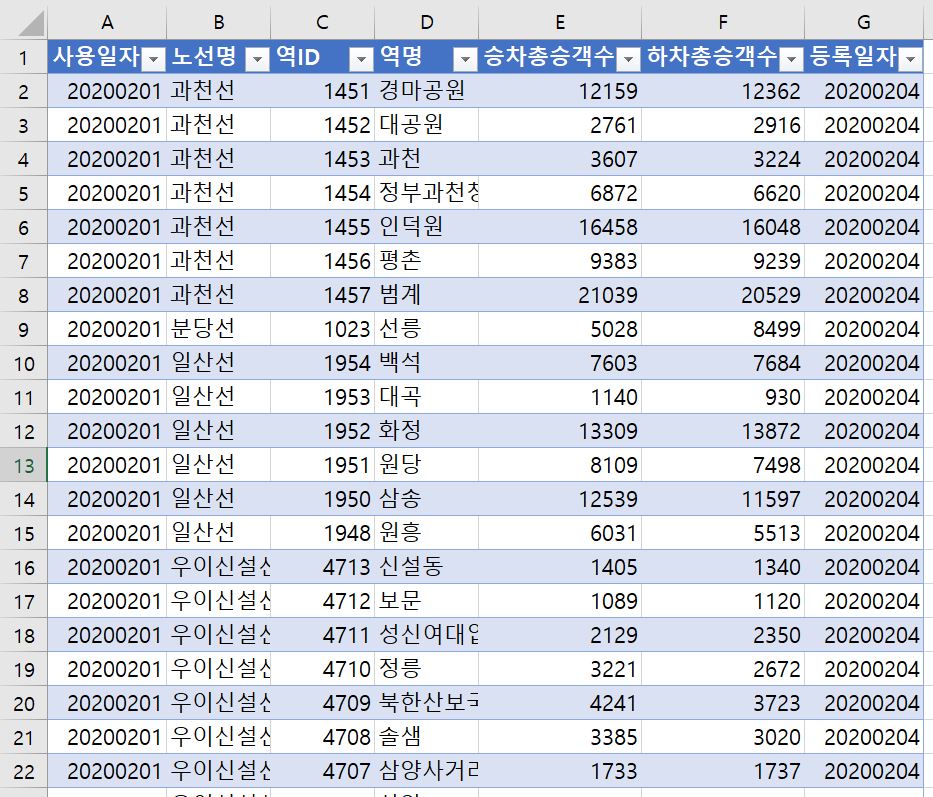
확인 버튼을 누르면 데이터가 다음과 같은 모양으로 변경될 것이다.
다음은 수집된 데이터 중 우리에게 필요한 자료들을 남기고, 필요하지 않은 것은 삭제하는 단계이다. 만약 삭제하는 것이 주저된다며 백업데이터를 만들어두면 된다. 시트를 복사하든, 파일을 통째로 복사하든, 각자 편한 방법을 선택하여 자료를 백업해두면 된다. 백업을 마쳤다면 삭제작업에 들어간다. 행과 열에서 선별적으로 데이터를 삭제할 예정이다. 열에서 삭제할 데이터는 역ID와 등록일자이다. 다음으로 행에서 삭제할 데이터는 두종류인데 첫째로 사용일자이다. 사용일자에서 2월 23일부터 3월 22일까지의 자료만 남기고 모두 삭제한다. 둘째로 노선명이다. 노선명에서는 2호선만 남기고 나머지 호선은 모두 삭제한다. 이 작업까지 마치고 나면 수집된 35,383행에 7열짜리 데이터가 1,450행에 5열짜리 데이터로 가공되어 있을 것이다.
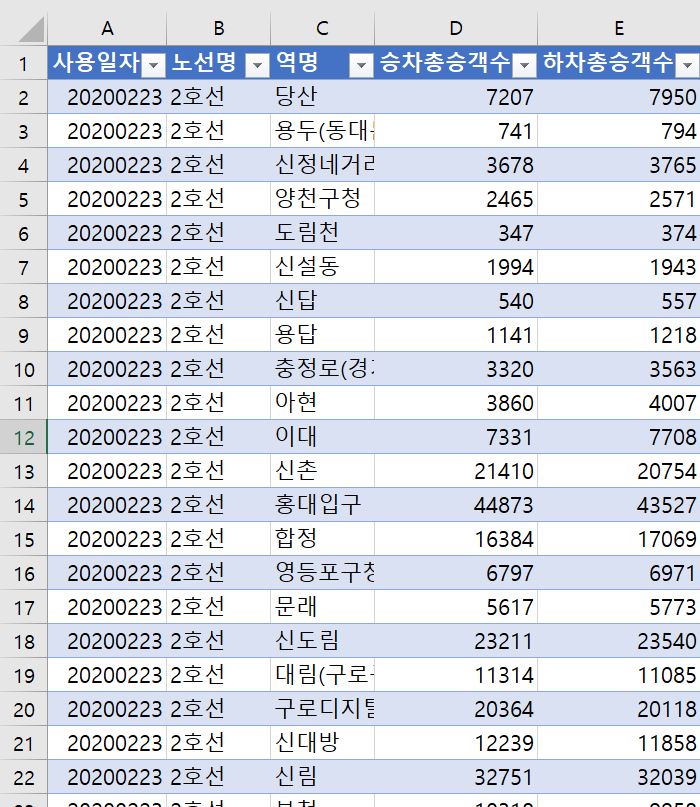
이렇게 하고 나면 피벗을 돌리거나 표를 만들 때도 더욱 간편하게 자료를 확인해볼 수 있다.
이상으로 데이터 분석 전 수집하고 가공하는 것에 대해서 알아보았다. 다음 포스팅은 데이터 분석과 시각화 기능에 대해 소개할 예정이다.